
基于python下的知识图谱的开发
该项目是我以及我们宿舍小组SSK第一个正式的项目,虽然之前也一起做过一个开源游戏,但其质量真的不敢恭维。相信这个项目在导师——刘旭红的带领下可以有较高质量的完成吧。这里我就一博客的形式记录一下我们的大致开发过程,其中会包含用到了那些技术,我从中学到了什么,以及部分代码记录,方便自己往后想要在其中某方面继续发展时翻看来用。
项目目的及简介
目的:用人话来说就是做一个类似关系图的东西,由于我们自己选择的方向是中医药材方面的领域,所以最开始的打算是根据不同药材的性味,化学成分,剂量等方面构建一个药材配方库,即通过一个药材的属性找到该药材并根据其属性找出该药材的相关配方,这个过程应该是双向的。上述皆为个人理解,因为暂时我们团队里面仍有部分意见未统一
简介:同目的。
项目分工及目前进度
分工:由于我们目前团队较小,而且沟通时分方便,且每个人现阶段真正会的技术也都相差不大并无特色专长,所以分工完全就是项目的一个部分布置下去之后大家一起做,最终谁做的最好就竞选成功 d=====( ̄▽ ̄*)b,但是这也导致了我们这种无专长的情况一直在持续…….
目前进度:目前主要还是数据的收集和整理,原计划该项目会持续一年的时间,但由于一个学姐的加入项目的工期从1年缩短到了3个月 (=。=),如果问题不大的话,我个人认为收集数据及整理已经基本完工了,下一步主要是确定一下项目方向然后,进行实体及实体关系的抽取,并导入neo4j数据库即可。我看网上都是直接将数据导入neo4j数据库然后数据库就可以自己导出一个关系图的
目前个人接触到的技术点
一.Scrapy爬虫框架
在数据采集的part我们主要应用了scrapy框架,主要是因为其相当的简便,相比于自己完整的写一个爬虫而言,scrapy框架已经将大部分代码写好,主要需要用户写的就只有一个spider类(爬取数据的逻辑类),其余的只剩下了一些pipeline的导入和setting的配置问题。这也是我第一次真正意义上的接触框架这个概念,原来看过一些视频上面说javaEE与javaSE的区别就是框架,而框架在实战中也扮演着一个重要的角色。所以这里就稍微的记录一下我在使用scrapy框架时的心得吧。
1、下载配置
在配置的时候看过很多很麻烦的方法——下载离线包什么的,其究其原因无非都是因为在国内直接pip install scrapy时由于网速不达标,导致各种报错,我这里直接用了一个镜像就下载好啦。命令行如下:
1 | pip install scrapy -i http://pypi.douban.com/simple --trusted-host pypi.douban.com |
我也不确定这个链接能撑多久,但到写本文之时仍然好使。
2、开始项目
这一步主要是在终端完成的不管是git bash,cmd,pycharm自带的终端都可以,只要键入以下命令行即可:
得到以下目录就算是成功了!!!
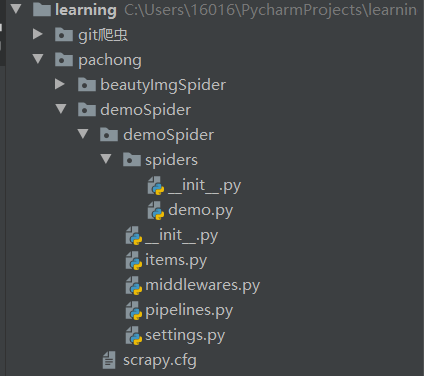
3、代码部分
在得到了目录之后我们主要的代码是写在parse函数中的,而参数中的response(请求响应)就是我们主要利用的东西。而上面的allowed_domains和start_urls则分别代表要爬取的网页不得超过allowed_domains,开始爬取的页面为start_urls,parse部分的代码主要用到了xpath和正则表达式两个工具获取网页中要爬取的内容,其中正则表达式充当了一个筛选的作用,而xpath则是获取内容的作用。这里推荐两款Chrome中非常有用的插件——Xpath Helper,regex matcher。中间的代码部分可参考如下:
1 | # -*- coding: utf-8 -*- |
这其中值得说一下的就是yield的时候用,yield的用法和功能类似于return,但是他可以不断返回(return返回一次然后就break了),而每次返回之后yield会暂时停掉,然后再等到循环进展到yield之后再一次返回一个,这里用yield不断地给服务器发送request,用以得到response,再将这个接收到的response用callback返回给detail函数进行细节上的筛选处理。
3、item的使用
上面的例子中我用的时候自建的item(item说到底就是一个dict),并没有使用scrapy自带的items,但大多数情况下是需要使用的,而items的配置主要就是如下面代码所示:
1 | import scrapy |
在需要使用到这些items时直接from ..items import ZhongyiyaospiderItem导入即可
4、pipeline的使用
1、导入文本文件中
可参考以下代码:
1 | import os |
2、导出图片到文件夹中
可参考以下代码:
1 | import scrapy |
这里需要注意一下,因为这里用到了scrapy里面的图片管道所以在setting中的配置也与文本文件的不同。
3、导入到csv文件中
可参考以下代码
1 | import os |
这里也需要注意一下,由于csv和excel文件好像不直接支持utf-8,导致即使在写入时用的是utf-8编码中文也会出现乱码情况,所以这里采用了另外一种utf_8_sigem……….这个好像也是。utf-8
5、setting的配置
首先是ROBOTSTXT_OBEY = False从True改为False,这里是问爬虫是否遵从robots协议,那我们当然是不拉 ~(~ ̄▽ ̄)~,要不然很有可能会导致想要爬去的数据人家不让你爬,你就废了。
其次就是

这里需要将注释去掉,这样才能开启管道。而在存入图片的时候的管道由于是ImagePipeline所以应该是这样

同时还需要加入图片的存储位置

最后这里需要说一下控制爬虫爬取速度的设置
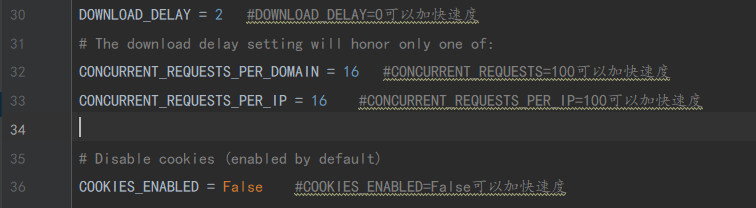
这里其实一般都是注释掉的,注释掉的时候爬取速度一般也不会太慢,如果很慢的话基本都是自己家网络问题,其中的DOWLOAD_DELAY默认为0,有时爬取太快的话网络请求不过来会有一个报错码为600多的报错,这时将DOWLOAD_DELAY调大点就好啦。
6、一点点的反反爬
有时有的网站在爬取的时候会有一个报错码403的错误,这时我们只需要在该网页中按下F12,并在Network中找到user-agent项并加到setting里即可

7、运行爬虫
直接在cmd,git bash,pycharm-terminal中键入scrapy crawl [爬虫名字]即可
总结:以上就是我在这次项目中接触到的scrapy爬虫的一些技术要点,像代理IP和中间件等更难的应用,暂时我还没有勇气去碰。虽然这次浅尝辄止了,但是如果未来有机会有精力的话还是可以继续研究一下的。
二.pandas数据清洗
由于我们之前爬取的数据主要是以csv和excel文件存储的,所以这里经过我们的搜查就选用了pandas这个库进行数据上的处理,主要就是一些数据上的去重和缺失补全(缺失删除),最后整理得出了大约1w条比较完美的数据,经过老师的许可,这1w条数据将会成为我们最终形成知识图谱的依据。
由于对数据的处理相对简单所以这里只用到了几个语句,这里暂时陈列一下:
a=pandas.read_excel('medicine.xlsx',index_col=None,na_values=['NA'])读取excel文档a=a.replace('[]',numpy.nan)因为原来的excel文件里我们用“[]”表示的空,所以这里用numpy里面的null替换一下方便后面对其进行缺失删除的操作a=a.dropna(how='any')这里就是将只要有空值的行就进行删除c=a.append(b)由于我一共处理了两个表就已经凑够了1w的数据量,所以这里直接进行一下拼接c=c.drop_duplicates()这一句是对拼接的表c进行去重操作c.to_excel("pandas_excel.xlsx")再导出到excel文件中
总结:这里可以看出其实pandas库还是非常好用的,对于去重补全的操作还是很简单的。
相关链接: