
SQL学习日记(2)
继上次写博库已经过了很久了,这期间大致学了一下html,然后就是跟着老师上课写作业。今日课余才想起来再去继续学一下SQL语言,并就此决定在这个礼拜就给他大致学完,上次的进度时停留在了查询语言的表的链接上,最近已经学到了表和数据库的增删改了。感觉曙光就在前方。
这两天可能会集中地更新一下SQL学习日志,这里我打算暂时先只学完SQL语句的基础版,而进阶版看具体情况而定。
该文章中所用到的相关表可在这里(密码:6yfe)下载解压并导入到数据库中。
SQL查询语句
99语法的表连接
在写上一篇博客的时候我只是初步的了解了一下表的的链接中的99语法和92语法,而经过一个多礼拜的磨炼,我对99语法的拼接有了很大的改观,越看越顺眼了,用起来也十分方便+强大。
主要还是99语法用的多了,上篇我大致介绍了一下链接的规则这里,而这次我就具体的介绍一下99版的表连接查询。 首先我们需要知道在SQL99版的表连接中,有两大主类的链接方式:
一、内连接
二、外连接
而我自己通过一段时间的使用,又把他俩进行了一个拆分重组,分为了三种主要使用的,两种基本不怎么用的:
主要使用:
内连接(【inner】 join on)
外连接(left 【out】 join on,right 【out】 join on)
基本不用:
全外连接(full join on)
交叉连接(cross join on)
笛卡尔乘积既然我们有了上述的新的分类,那么就让我们开始挨个的了解一下吧。
我们首先要知道所谓的链接是用来干嘛的,其实说白了就是你要查询的一个东西他涉及到了两个表中的多种属性,此时如果我们再仅仅依靠某一张表是无法完成查询的,所以我们就需要用链接语句将两个或者多个表(根据要查询[或是插入]的内容来决定表的数量)链接成为一个新的表,这样我们就可以在这个新的表中进行查询(与之前的查询就没有太大区别了)。
Inner join on
Inner join on可以说是使用频率最高的一种连接方式了,其根本的原理类似于集合运算中的交集运算,可参考以下图片示例:
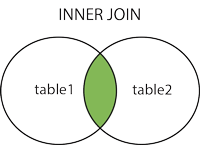
而其具体的语法可参考代码:
1
2
3
4SELECT <SELECT LIST>
FROM A
JOIN B
ON A.id=B.id具体例子如下:
1
2
3
4
5
6
7
8
9SELECT
e.`employee_id`,
e.`last_name`,
d.`department_name`
FROM
employees e
JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_name` LIKE "A%" ;运行截图如下:
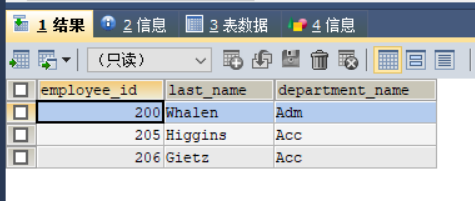
这里我们可以看到我们是将departments表与employees表关联了起来(inner是可省略部分),然后以on后面的语句作为筛选条件将两者的交集部分形成一个新的表,并查询了
departments_name、employee_id、last_name这三个属性,同时加入了一个where筛选条件,也就是说在这个由内连接而新生成的表中我们是可以不仅可以同时查询原本两表分别的内容,且我们还可以像正常表一样给他加入筛选语句。这里的e和d是给表起的别名,方便输入。注意:
1.这里的例子用的是等值链接,还有一种非等值链接,只需将on后面的筛选条件中的等号换为between and等关键字即可对一定范围的数据进行筛选。
2.除了两个不同的表链接以外还可以实现自连的操作,即自己与自己相连可参考代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15SELECT
CONCAT(
e.`last_name`,
'管理着',
em.`last_name`
) '姓名',
CONCAT(
em.`manager_id`,
'管理着',
em.`employee_id`
) 'id'
FROM
employees e
JOIN employees em
ON e.`employee_id` = em.`manager_id` ;运行截图如下:
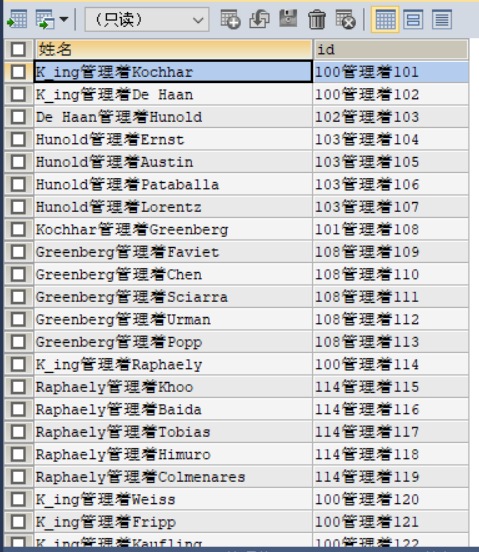
Left join on&Right join on
由上面的inner join的例子我们可以了解到两表连接就是把两个表拼接成为一个新的表,而inner join对其进行的运算相当于两个表取交集,而left join和right join则更像是集合运算中的差运算,可参考图片
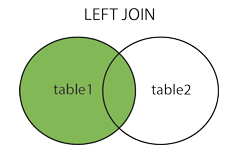
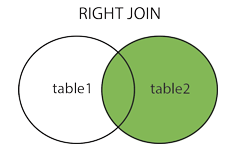
具体可以参考以下代码:
1
2
3
4SELECT <SELECT LIST>
FROM A
LEFT JOIN B
ON A.id=B.id1
2
3
4SELECT <SELECT LIST>
FROM B
RIGHT JOIN A
ON A.id=B.id具体例子如下:
1
2
3
4SELECT *
FROM beauty b
LEFT JOIN boys bo
ON b.`boyfriend_id`=bo.`id`运行结果如下:
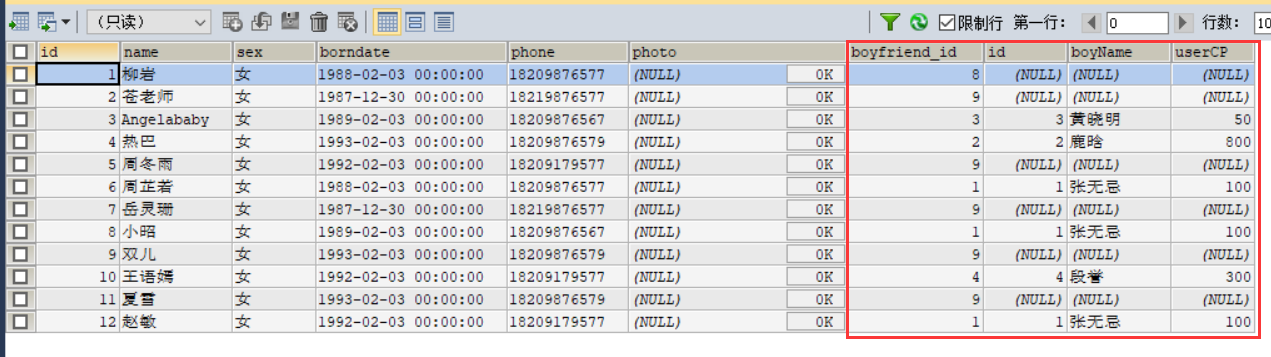
我们可以看到此时我们使用的是left join语句,其意思就是以左表(from后面的那个)为主表,右表(left join后面那个)为辅表。此时的运行结果出现了之前inner join中未出现的情况——右边用红框圈起来的表中包含了很多null,这是因为主表中此时没有与之相匹配的字段,即有的女神的男朋友不在男朋友表中,而根据我们的集合运算来看,此时我们就可以反向筛出那些A表(主表)中没有而B表(辅表)中有的字段使用:
where primary key is null,而这也是外连接最常用的一种用法。而由上面参考代码我们可以知道其实左外链接和右外链接是可以互相转换的,只需要换一下关键字和主附表之间的位置关系即可一般还是左外用的比较多。 这里我们到了不常用的链接的部分,这里我就只给出相对应集合运算关系图和参考代码了,就不给具体例子并分析了。
full join on
对应的集合运算应该是并集关系,关系图如下:
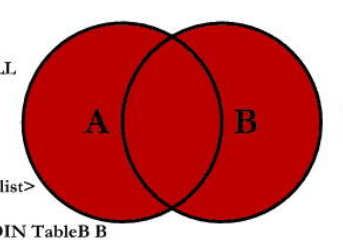
具体可以参考一下代码:
1
2
3
4SELECT <SELECT LIST>
FROM B
FULL JOIN A
ON A.id=B.idcross join on
这个交叉链接比较特殊,好像在集合运算中没有具体的运算与其对应,大致可以理解为集合中的笛卡尔积的形式:A={a,b}B={0,1,2}==》A*B={(a,0),(a,1),(a,2),(b,0),(b,1),(b,2)}
具体可以参考一下代码:
1
2
3
4SELECT <SELECT LIST>
FROM B
CROSS JOIN A
ON A.id=B.id小结:至此表的链接基本就已经搞定了,全部都用的是99语法
92语法也没有这么多东西,然后最后要强调一下的是,虽然表的链接本质是将多个表接在了一起但其中并没有新增新的元素,所以在对其进行进一步筛选的时候我们是用不到having语句的,不要将其余group by语句执行后生成的那个表混淆。子查询
子查询就如同他的名字一样,就是个套娃。我们一般在查询的时候常常会出现这种情况要在一个前提下再去进行进一步筛选才能选出,比如:我想要找一个北京信息科技大学的计算机学院的男生。那么我这里就需要先在北京的大学中筛选出北京信息科技大学,然后再对北京信息科技大学这个查找出来的表进行进一步的筛选
看似这个可以用and来替代,这时候我们就需要用到子查询。这里先放上其具体语法:
1. 子查询放在where(having)后面
1
2
3
4
5
6
7SELECT *
FROM A
WHERE A.condition=(
SELECT <SELECT LIST>
FROM B
WHERE B.condition
)我们可以看到,其实说白了就是一个套娃,在一个查询的里面在套入一个查询,但是这里如果用的是“=”的话那么子查询中的结果必定要是一个单个的值,如果子查询的结果为多行单列或是多行多列的值的集合,那么就需要用到in等模糊查询的关键字对其进行筛选了。还有一点就是虽然我这里的例子用的是两个不同的表(可以看出这里是不需要量表链接的,前提是B表筛选出来的值在A表中有与之对应的),但其实也可以一个表和自己进行子查询。
具体代码例子:
1
2
3
4
5
6
7SELECT *
FROM employees e
WHERE e.manager_id=(
SELECT d.`manager_id`
FROM departments d
WHERE d.`department_id`=30
)运行结果如下:

2. 子查询放在from后面
1
2
3
4
5
6
7SELECT <SELECT LIST>
FROM(
SELECT <SELECT LIST>
FROM B
WHERE B.condition
) A
WHERE A.condition相比第一种在where后面加入的查询这里的查询要相对难上一些,这里我们可以看到是将子查询返回的结果作为了一个全新的表进行了二次查询,这也就要求子查询返回的要是一个表而非单个值,同时要对子查询生成的新的表进行重命名,以保证对其再次进行操作时有一个可以用来调用的名字(包括子查询结果中的需要进行二度操作的列都需要单独命名)。
具体代码如下:
1
2
3
4
5
6
7SELECT *
FROM(
SELECT d.`department_id` 'd_id',d.`department_name` 'name',d.`location_id` 'l_id',d.`manager_id` 'm_id'
FROM departments d
WHERE d.`department_name` LIKE 'C%'
) d
WHERE d.d_id>150运行结果如下:
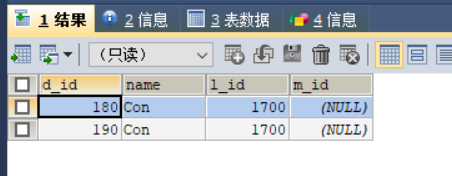
3. 子查询放在select后面
1
2
3
4
5
6
7SELECT A.<SELECT LIST>,(
SELECT B.<SELECT LIST>
FROM B
WHERE B.condition
)
FROM A
WHERE A.condition由上面的代码我们可以大致感受到其实这个select的子查询跟多表链接基本没有啥太大差别,而且更加麻烦,所以还不如使用多表链接来的方便,所以这就是为什么它相比前两种子查询使用次数没有那么多的原因。
具体例子如下:
1
2
3
4
5
6
7SELECT e.last_name "部门id为30的员工",(
SELECT d.`department_name`
FROM departments d
WHERE d.`department_id`=30
) "id为30的部门的名称"
FROM employees e
WHERE e.department_id=30运行结构如下:
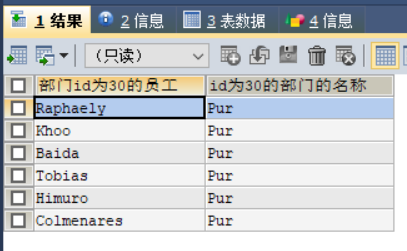
4. 子查询放在exists后面
1
2
3
4
5
6
7SELECT <SELECT LIST>
FROM A
WHERE EXISTS(
SELECT <SELECT LIST>
FROM B
WHERE B.condition
)到这里的exists的子查询用的情况就非常非常少了,因为他可以被很多种方法代替,而且还都比他方便。但是这里还是说一下,其中exists这个关键字的作用就是判断其括号中的字段是否存在数据,如果存在,那么返回1,如果不存在那么返回0。
1
2
3
4
5
6
7SELECT d.department_name
FROM departments d
WHERE EXISTS (
SELECT *
FROM employees e
WHERE e.`department_id`=d.department_id
)上面这里用到了92语法的表的连接
具体运行效果如下:
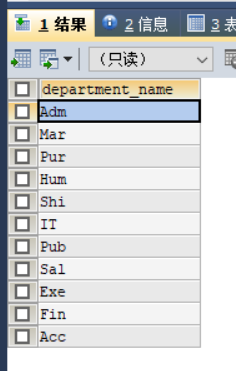
注意:上面说where使用的例子都是标量子查询也就是用的最多的单列单行查询,其实子查询还分为单列多行和多列多行的,只需要将原来的”=”换为in(主查询的元素是否在子查询查询出来的列表中),any,all等模糊查询的关键词即可。
小结:这里我们可以发现,其实很多时候子查询都像是起到了表的链接的作用,但其本质又与多表链接不同,多表链接是真的将表连在一起之后再进行一步筛选,而子查询更像是筛完一个表之后再继续用产生的结果进行二次筛选,而并没有将表连接起来。而且有很多时候子查询的功能要比表的连接更丰富强大。
3.联合查询
1
2
3
4
5
6
7SELECT <SELECT LIST>
FROM A
WHERE A.condition
UNION
SELECT <SELECT LIST>
FROM B
WHERE B.conditionunion关键字主要作用就是将多条查询语句链接起来形成一个新的表,看上面给出的例子好像他的作用可以被表的链接所替代,但是那是在两个表存在相同的关键字段可以链接的时候,如果两个表之间并没有可以用于连接的关键字段时我们仍需要将两个不相干的表连在一起,union关键字 就起到了作用,同时上面的代码只是举了一种例子,实际应用中很多操作语句都可以用union进行连接。具体例子如下
这个例子举得不好:1
2
3
4
5
6
7SELECT d.location_id
FROM departments d
WHERE d.department_id>50
UNION
SELECT e.department_id
FROM employees e
WHERE e.department_id>50运行结果如下:
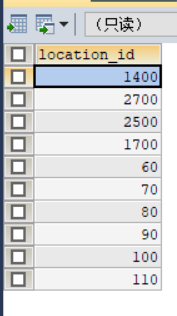
4.分页查询
分页查询主要就一个关键字
LIMIT其作用就是限制查询结果个数,其后面跟着两个参数【offset,】size第一个是他的起始位置(默认为0即第一行开始),第二个是想要显示的条数。具体代码如下:1
2
3select <select list>
from A
limit <offset> size值得注意的是limit的位置一定要在查询语句的最后比order by关键字更靠后
具体例子如下:
1
2
3
4SELECT e.last_name,e.salary
FROM employees e
ORDER BY e.salary DESC
LIMIT 10运行结果如下:
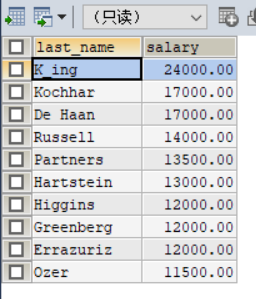
总小结:到这里所有的查询语句大致的都在此列举完了,下面我们要进入了数据,表,库的增删改操作了。
数据库的增删改
增
1
CREATE DATABASE IF NOT EXISTS <database_name>;
这里的IF NOT EXISTS是用来判断该库是否存在的,用来减少报错的,同理可应用到后面的各种创建和删除操作。
删
1
DROP DATABASE IF EXISTS <database_name>;
删库跑路 d=====( ̄▽ ̄*)b改
1
ALTER DATABASE <database_name> CHARACTER SET encoding;
这句是用来改库的编码形式的一般默认为
UTF-8
表的增删改
在进行表的增删改之前我们现需要知道一个很重要的概念约束
这里由于犯懒就暂时就先只贴一张菜鸟教程里的图片了

其中的
foreign key是标准的表约束,即写在表的最后,其余的都和做列约束,即关键字写在每个创建列的子句的后面。还有一点就是foreign key的值必须也为key(可以是primary key,unique,foreign key)。其中CHECK在mysql中不起作用增
1
2
3
4
5
6
7CREATE TABLE table_name
(
column_name1 data_type(size),
column_name2 data_type(size),
column_name3 data_type(size),
....
);这里需要具体说明几点:
- 每个data_type后面是可以跟“约束”的,约束就是对该列的一些限制条件。
- 这里在表中添加的仅仅是一个表的结构,数据此时还未插入到其中,此时查表只会有最顶部的结构信息(就是只有列名)。
- 每个表最好都有主键(primary key)
1
CREATE TABLE <table_name> LIKE <anoter_table_name>
这句话也是用来创建表的,但是这里是直接将另一个表的结构复制到新建表中
1
2
3CREATE TABLE <talbe_name>
SELECT <SELECT LIST>
FROM <another_table_name>这句话同样是用来创建表的,相比于上面那个复制的方法,这个加入了select语句,这样我们就可以选择自己想要的列来进行复制,但同时也出现一个问题
好处就是被复制表中的数据也会被复制到新建的表中(这时可以用下面要讲的删除数据的操作进行清理)。删
1
DROP TABLE <table_name>
改
1
ALTER TABLE <table_name> CHANGE COLUMN old_column_name new_column_name data_type(size)
这个语句是用来更改表中列的名称的,但是我实在是不明白为什么要在这个的最后加入数据类型。。。。。。
1
ALTER TABLE <table_name> MODIFY COLUMN column_name new_data_type(size)
这个语句是更改指定列的数据的类型的,值得一提的是其中
varchar类型在不同size下属于不同的数据类型,所以如果要给字符型扩容需要用到此语句。此外这句还有一个作用,就是当
new_data_type(size)后面加入约束后,是可以对该列的约束进行修改,删除,添加等操作的。1
ALTER TABLE <old_table_name> RENAME <new_table_name>
这个语句是为表改名的。
1
ALTER TABLE <table_name> ADD COLUMN <new_column_name> data_type(size)
这句是给表新增列用的,这里可以在
data_type(size)后面加入first来将新加入的列置于表的最前端。1
ALTER TABLE <table_name> DROP COLUMN <column_name>
用来删除列的。
表中数据的增删改
增
1
2
3
4
5
6INSERT INTO table_name
VALUES (value1,value2,value3,...),
(value1,value2,value3,...),
(value1,value2,value3,...),
(value1,value2,value3,...)
...;这是第一种方法,因为没有指定列名所以需要将所有列的数据都写入value中。
1
2
3
4
5
6INSERT INTO table_name (column1,column2,column3,...)
VALUES (value1,value2,value3,...)
(value1,value2,value3,...),
(value1,value2,value3,...),
(value1,value2,value3,...)
...;这种插入方法相比第一种,在table_name后面加入了需要插入的列的属性,所以此时我们只需要插入指定列的值即可
1
2
3
4INSERT INTO table2
(column_name(s))
SELECT column_name(s)
FROM table1;这个的原理同上面表的创建时的作用其中第一个
(column_name(s))可省,此时第二个(column_name(s))可改为*。删
1
2DELETE FROM table_name
WHERE some_column=some_value;这就是对数据的删除,不会删除表原本的结构(即只删行不删列),如果此时我们将where子句删掉,那么我们就会删除该表中的所有数据,即上文提到的数据清理。
改
1
2
3UPDATE table_name
SET column1=value1,column2=value2,...
WHERE some_column=some_value;这是一般表的正常改法,即批量更改,只要符合where子句后面的条件就会被更新,如果没有where子句那么整个表都会被更新。
1
2
3
4
5
6
7
8UPDATE <table_name>
SET <need_change_column> = CASE <primary_key(some_value)>
WHEN <some_value> THEN value1
WHEN <some_value> THEN value1
WHEN <some_value> THEN value1
WHEN <some_value> THEN value1
...
END这个更新语句相比上面那个就会灵活很多,主要的应用场景就是如果在表中新增加了一列,此时如果用第一个更新数据的方法就会很麻烦,需要 一个一个改,而这个语句则可以一次性全改掉。
具体例子:
1
2
3
4
5
6
7
8UPDATE student
SET score =CASE id
WHEN 1 THEN 100
WHEN 2 THEN 95
WHEN 3 THEN 90
WHEN 4 THEN 96
WHEN 5 THEN 93
END运行之前截图如下:
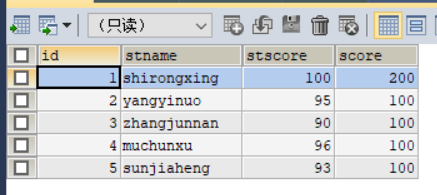
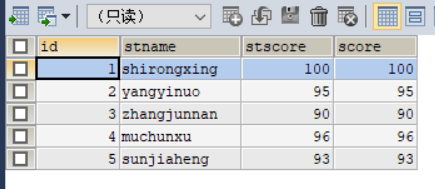
运行之后截图如下:
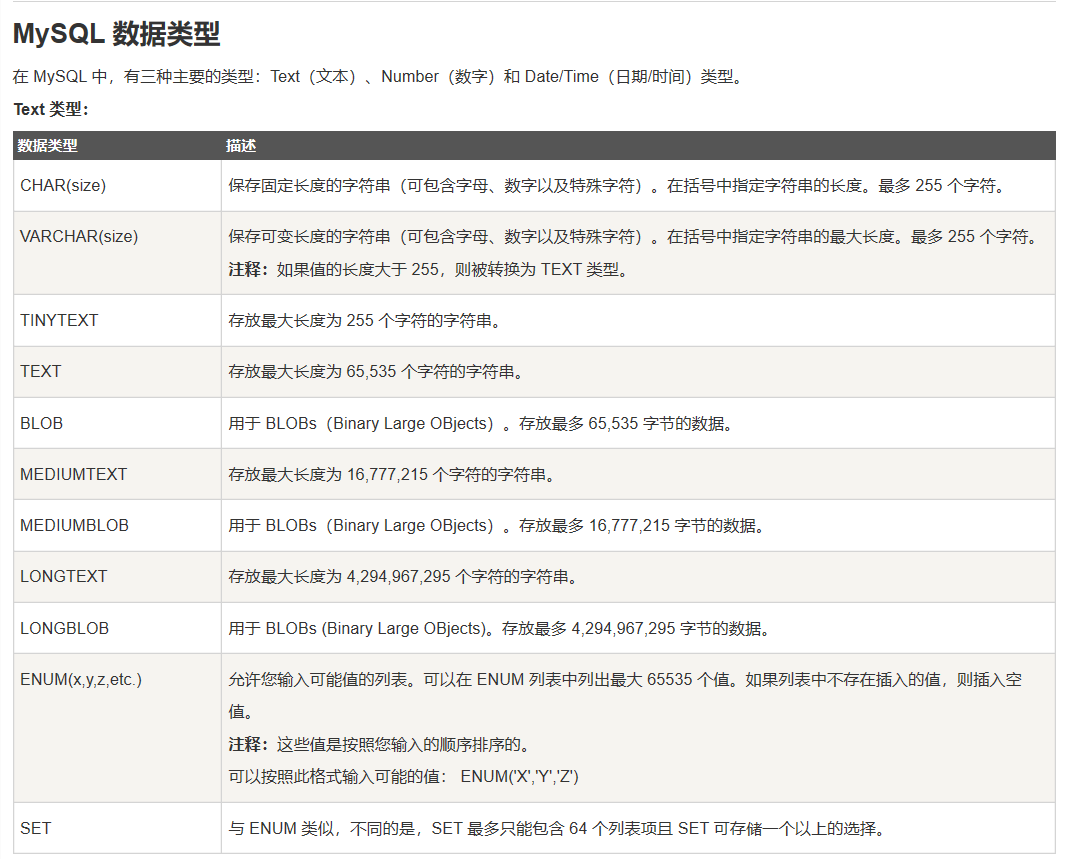
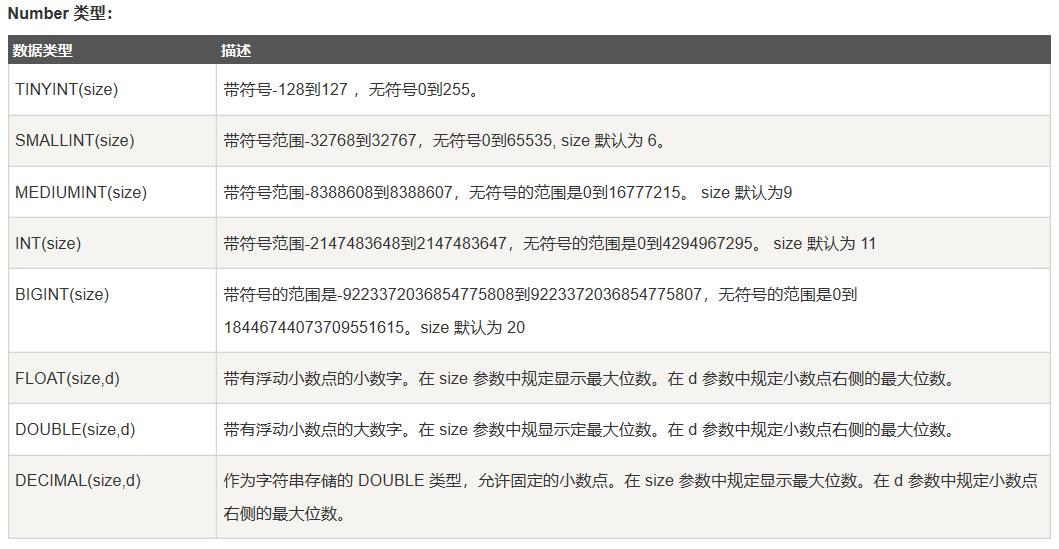
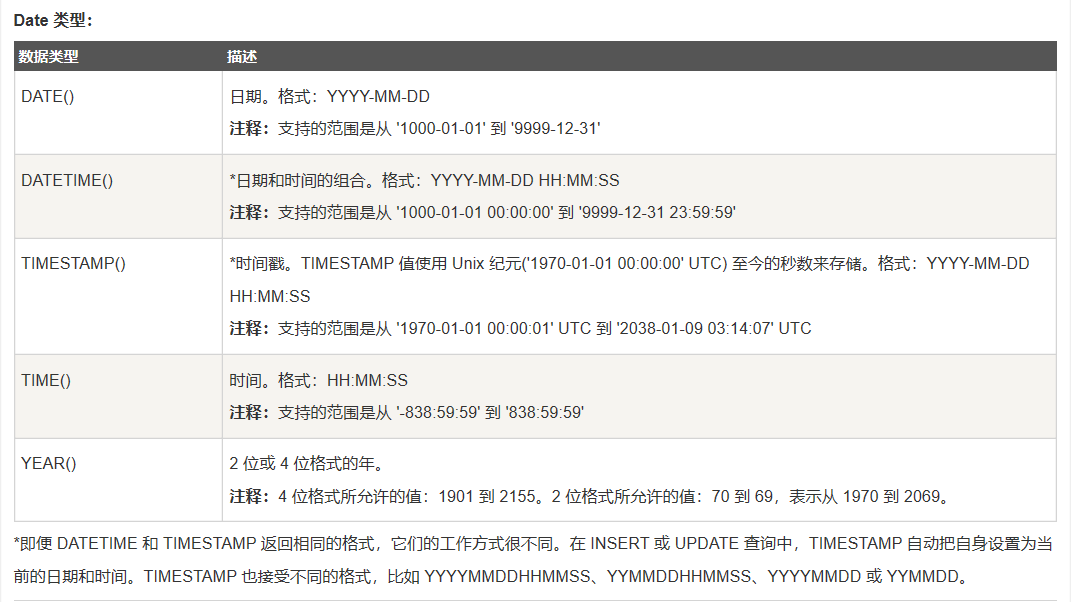
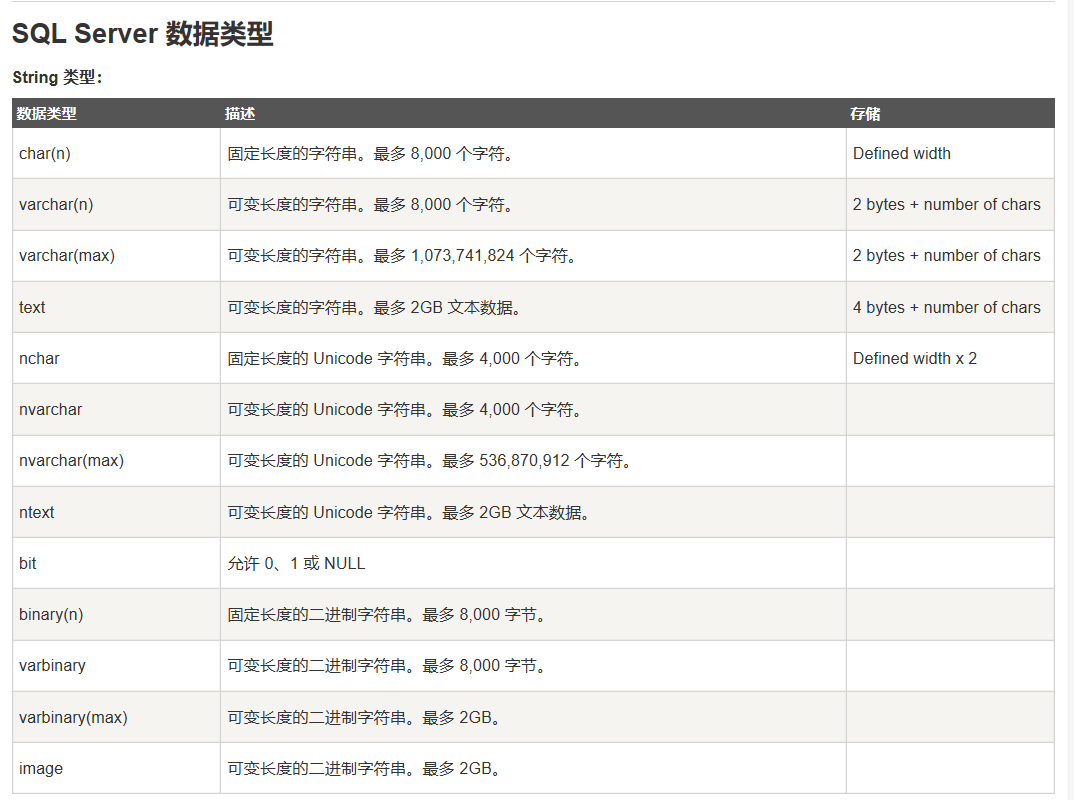
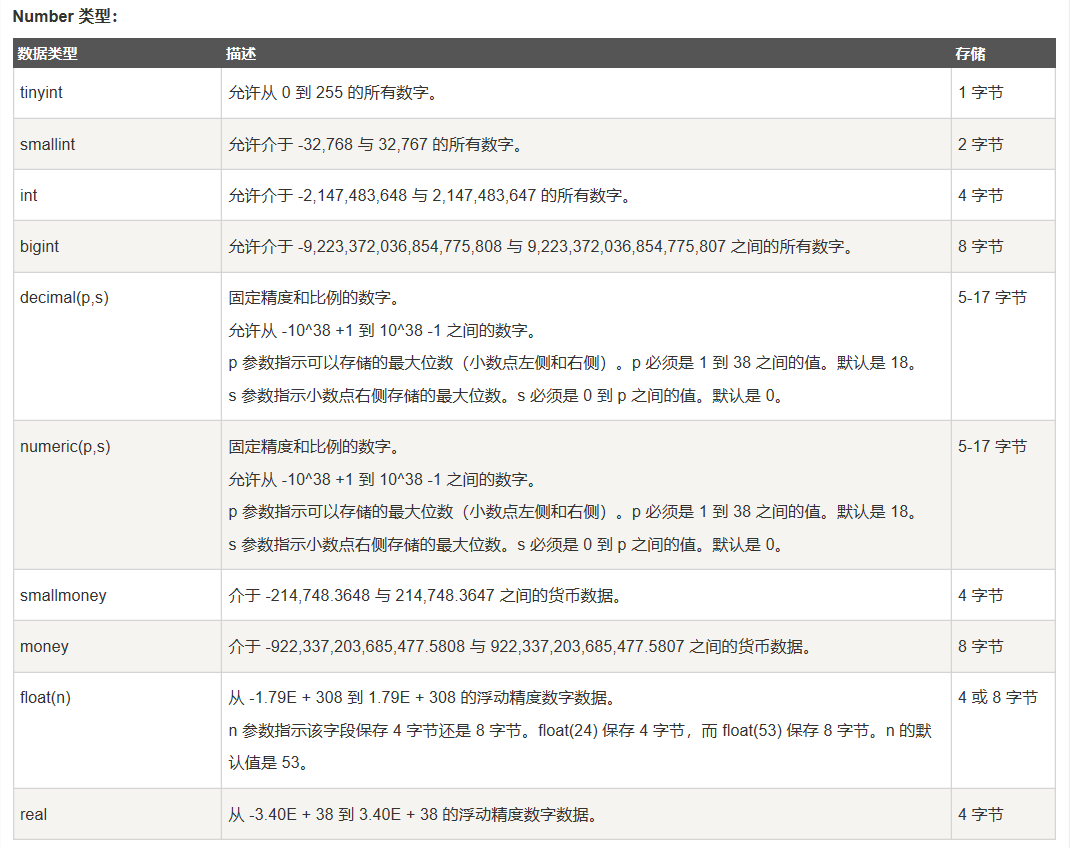
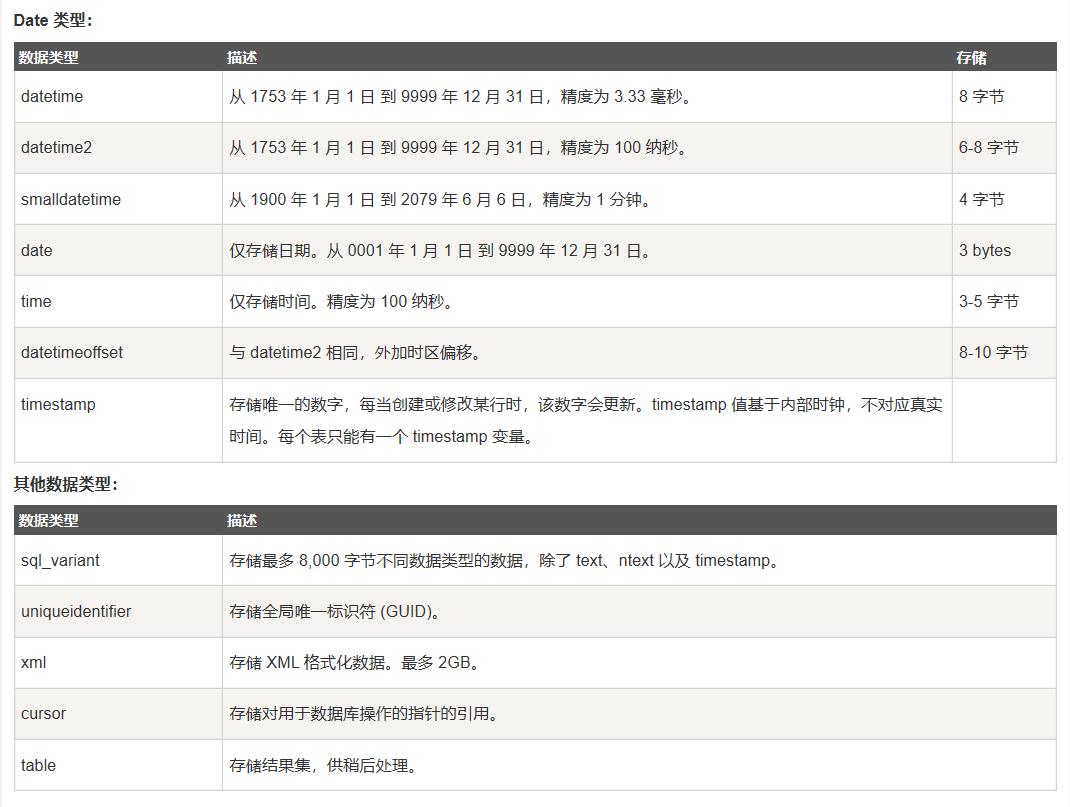
数据库中的数据类型
这里借用一下菜鸟教程中的数据类型的列表:
MySQL:
SQL Server:
这里附上我个人学习的途径: