
SQL学习日记(3)
这次更新完了之后sql中的基础部分主要是跟着b站那个视频学的,而且暂时只学了前178P基础部分应该就大致结束了,其中有很多的内置函数并没有给出,或仅仅是摆在那里。想着是等回头用到的时候再去查,然后就是看了看之前自己更的第二篇sql日记,真的好长啊= =搞得我自己都不想再去看第二遍……而且很累,所以这第三篇就不说那么细了,具体的东西到时候用到了再查就好。然后昨天晚上花了一些时间大致了解了一下JDBC(java代码+sql查询语句),所以下一篇应该就是它了。
sql事务
sql事务其实本身的作用就像是一个绳子,将多条sql语句绑定在一起,使其成为一个模块,要执行都执行,要回滚都回滚(如果一个事务中的sql语句执行到一半时发生错误,那么整个事务都会回滚)。这里有个具体的例子可以用来体会一下他的具体效果:

但其实他的具体属性还有很多上述图片给出的只是他最常用的原子性。这里将b站原视频中提到的属性进行一下罗列:
1.原子性:原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生
2.一致性:事务必须使数据库从一个一致性状态转换为另一个一致性状态。
3.隔离性(个人认为的难点):事物的隔离性是指一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事物是隔离的,并发执行的各个事物之间不能互相干扰(其实有点像java中线程的管理)
4.持久性:持久性是指一个事务一点被提交,他对数据库中的改变就是永久性的,接下来的其他操作和数据库故障不应该对其造成任何影响(举个例子:像sql中自带的update,create,delete等等都是隐式事务,即sql中自带的)
知道了上面的几个属性,我们接下来来具体操作一下所谓的事务。
首先我们需要明白一个点就是,事务的操作一般只针对于表,数据,数据库的增删改,因为查其实并没有对表进行永久性的改变,所以一般其占据的位置只是增删改的从属位置。
接着我们看一下事务的操作语句:
1.首先是事务的开启
set autocommit=0; 这里是将autocommit(自动提交)给关闭,原因是原本的隐式事务是开启这个的,而现在我们将它关闭之后,等回头将几个隐式事务绑定之后再进行一次提交,以形成自己的事务。
2.编写我们自己的事务(显式事务)
1
2UPDATE student SET score=100 WHERE id=1;
UPDATE student SET score=86 WHERE id=4; 这里我就以更新学生成绩为例,即id为4的学生给id为1的学生10分,那么这里就是将这两条sql语句进行了一个绑定。如果我们没有进行第一步启用事务直接进行这两句话的话,那么他们就分别是两个不同的事务,如果在执行完第一句之后,系统突然断开连接导致第二条sql语句没有执行的话,那么学生1就会凭空多出10分,而学生4也没有减少10分。这里我们开启事务之后二者成为了一个事务,那么如果还是在执行完第一句之后断开连接。这时,就会发生回滚,即学生1的成绩没变,学生4的成绩也没变。当然这里的事务的绑定不仅限于更新数据,增删一样好使。
3.关闭事务
1
2
3commit
或者
rollback 通过第二步我们成功的同步改变了我们的多条数据,而此时数据仅仅是改变了并没有真正的提交到数据库中,如果此时我们不结束事务直接断开链接的话,那么我们之前所更改的事务在我们再一次连接的时候就会恢复原样,所以我们为了数据的持久性,需要用
commit来结束事务,commit就是提交,提交过后我们的数据就会永久的保存在数据库中,那么rollback又是什么呢。其实就是之前我么常常提到的回滚,即恢复数据。这里的恢复是指恢复上一个记录,而不能多次回滚,这里举个例子,如果我第一次将A的成绩从90更改为了100,此时如果我回滚,那么就可以回滚到90,但如果此时,我们先将A的成绩从90改为100,然后再将100改为110,那么在改成110之后我使用回滚,A的成绩会回滚到90而不是100。可以理解为后修改的110将原来修改的100的数据给覆盖了。这里补充一点,其实回滚还有一个特殊的伙伴,就是回滚点,其作用类似于我们程序调试中的断点。使用语法为:
1
2>savepoint a
>rollback to a其中的
savepoint a是插在你想设置断点的语句的后面的。 接下来我们要迎来第一个难点了
主要是因为需要记得单词比较长…. 事务的隔离级别:
这个事务的隔离级别有点像java里面的线程并发问题。
首先我在这里说一下事务并发可能会出现的几个问题:脏读,不可重复读,幻读。
然后我们这里再说一下应对这几个问题的隔离级别:
read uncommitted(读取未提交数据),read committed(读取已提交数据),repeatable read(可重复读),serializable(串行化)。 其中每个隔离级别对应着一个问题的解决,第一个
read uncommitted是级别最低的,是无法解决任何问题的,其余的越往后隔离级别越高,其耗费的时间也就越久,所以一般最后一个隔离级别虽然他可以解决所有问题但一般不用他,其中repeatable read是mysql自己默认的。 知道了问题的解决方法我们来说一下要怎么更改和查看隔离级别:
查看隔离级别的语句:
1 | SELECT @@transaction_isolation; |
更改隔离级别的语句:
1 | SET SESSION TRANSACTION ISOLATION LEVEL <隔离级别类型>; |
然后就没什么了,其中具体的那几个问题的意思可以自行百度,这里就暂时不科普了,然后就是其实说了这么多,如果我们只是对一个连接进行操作的话,一般默认级别就够用了,即使多个链接同时进行事务的并发的话,其中的幻读对查询的操作影响也比较小(个人认为)。
至此有关于事务的绝大部分事情就都说完了,sql高级篇的没算在内;
视图
视图说白了就是一个虚拟的表,他主要是用于保存一定的复杂sql语句,可以是增删改查中的任意一种,其可以理解为子查询的一种进化,只不过他主要是保存了sql语句的逻辑,而非真正的表,所以相比于真正的表其优点有以下几点:
1.增加代码的可重用性,这点类似于java中的方法,只要视图创建出来之后我们就可以反复的“调用”它。
2.所使用的内存极小,这个的原因在于视图的本质是在创建时对指定的sql语句进行一个类似于预编译的操作,从而保存了sql语句中的逻辑形成一个虚拟的表,而非真实的表
3.减少代码的冗余,当一段代码重用次数很高的时候,我们就可以把它“封装”成为一个视图,使用到的时候直接将视图看做一张表即可。
讲了视图那么多好处,那么咱们就来看一下具体的代码是什么:
视图的创建
1
2
3CREATE VIEW <视图的名字>
AS
<复杂的查询语句>视图的使用
1
SELECT <查询列表> FROM 视图
这里的使用只是最简单,实际上之前所有的查询语句都可以在视图上使用,包括多表的链接(将视图作为一个表即可)。
视图的修改
1
2
3CREATE OR REPLACE VIEW <原来视图的名字>
AS
<修改后的复杂的查询语句> 这个语句同样也可以应用到视图的创建上,因为其本身就是一个创建。这个是对视图的修改,而不是对视图的更新,更新下面我们会单独说。
视图的更新
1
2
3
4
5INSERT INTO <视图名字> VALUES(value1,value2,value3.....)
UPDATE <视图名字> SET old_value=new_value WHERE <筛选条件>
DELETE FROM <视图名字> WHERE <筛选条件> 其实说白了就和对数据的增删改一样,但是这里我们要注意一个点,就是虽说这里是对视图的修改,但如果一旦修改了视图中的数据,那么与这个视图相关的表中的数据也会随之变化,所以一般来说为了安全,视图会将权限设置为只读。而且有很多情况是无法更新视图。
视图的删除
1
DROP <视图名字1>,<视图名字2>,<视图名字3>,<视图名字4>.......
和表的删除一样,只不过视图的删除可以多个同时删除。
视图的查看
1
2SHOW CREATE VIEW<视图名字>;
DESC <视图名字>好像是没有
show views这个命令的,也就说我们在doc下好像没法看视图列表。变量
变量和事务一样分为隐式变量和显式变量,其中隐式变量即系统自带的显式变量则是我们自己创建的。
隐式变量
隐式变量分为全局变量和会话变量,区别在于作用域:全局变量的作用域是每次连接,而会话变量的作用域是仅仅这一次连接。
隐式变量的查看
1
2
3
4查看所有全局变量:
SHOW GLOBAL VARIABLES;
查看所有会话变量:
SHOW SESSION VARIABLES;1
2
3
4
5
6查看单条全局变量:
SELECT @@global.<变量名>;
查看单条会话变量:
SELECT @@<变量名>;
或
SELECT @@session.<变量名>;我们可以看到单条查询的时候默认的是局部的。
隐式变量的修改
1
2
3
4修改全局变量:
SET @@global.<变量名>=修改值;
修改会话变量:
SET @@<变量名>=修改值;后面我们设置显示变量的时候也是有用set。
显示变量
显示变量也叫自定义变量即我们自己定义的变量,其也分为两种:用户变量,局部变量。同样的二者的区别也只在于作用域不同:用户变量可以作用于单次连接的所有地方,而局部变量只呢作用于定义它时的begin到end之间,同时其在定义时还必须在begin~end中的第一行。
sql中的显示变量为弱类型变量。
显示变量的创建
1
2
3
4
5
6
7用户变量:
SET @用户变量名=值;
SET @用户变量名:=值;
SELECT @用户变量名:=值;
局部变量:
DECLARE 变量名 数据类型;
DECLARE 变量名 数据类型 DEFAULLT 值;用户变量后面的两种方法一般不用,记第一种就好了。一定要记住用户变量名不管是使用还是定义还是赋值都要带着@。
显示变量名的赋值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16用户变量:
方式一:
SET @用户变量名=值;
SET @用户变量名:=值;
SELECT @用户变量名:=值;
方式二:
SELECT 字段 INTO @变量名
FROM 表;
局部变量:
方式一:
SET 局部变量名=值;
SET 局部变量名:=值;
SELECT @局部变量名:=值;
方式二:
SELECT 字段 INTO 变量名
FROM 表;其中方式二查询过后的值必须为一个才可以赋值给变量。
显示变量名的使用
1
2
3
4用户变量:
SELECT @用户变量名
局部变量:
SELECT 局部变量名
存储过程和函数
都类似于java中的方法。
存储过程
在创建存储过程之前我们要先知道一个关键字
delimiter他的作用是重置结尾的结束标志符,重置的这个的原因是在END后面我们不能再仅仅依靠;来结束,这样会与END之前的存储方法体搞混。所以在创建存储过程前我们需要先去执行delimiter $$其中$$可以替换成任意字符。而这个语句改变的是本次链接中所有语句的结束符,所以在使用完这个语句之后我们的其他操作也必须使用新规定的结束符来结尾。但存储方法体的结尾仍应使用;结尾。注意:在使用
delimiter关键字是千万不要加;,要不然他会将;也算在自定义结束符中。 存储过程的创建
1
2
3
4
5DELIMITER $$
CREATE PROCEDURE 存储过程名(IN(传入参数)|OUT(传出参数)|INOUT(传入传出都可以) 参数名 参数类型)
BEGIN
存储方法体体(大部分是sql语句中的增删改操作,查主要用函数)
END$$上面的基础格式就是存储过程的创建样板,具体的我会举出四个不同的示例来演示不同的参数的模式。
1.无参存储过程
1
2
3
4
5
6
7
8DELIMITER $$
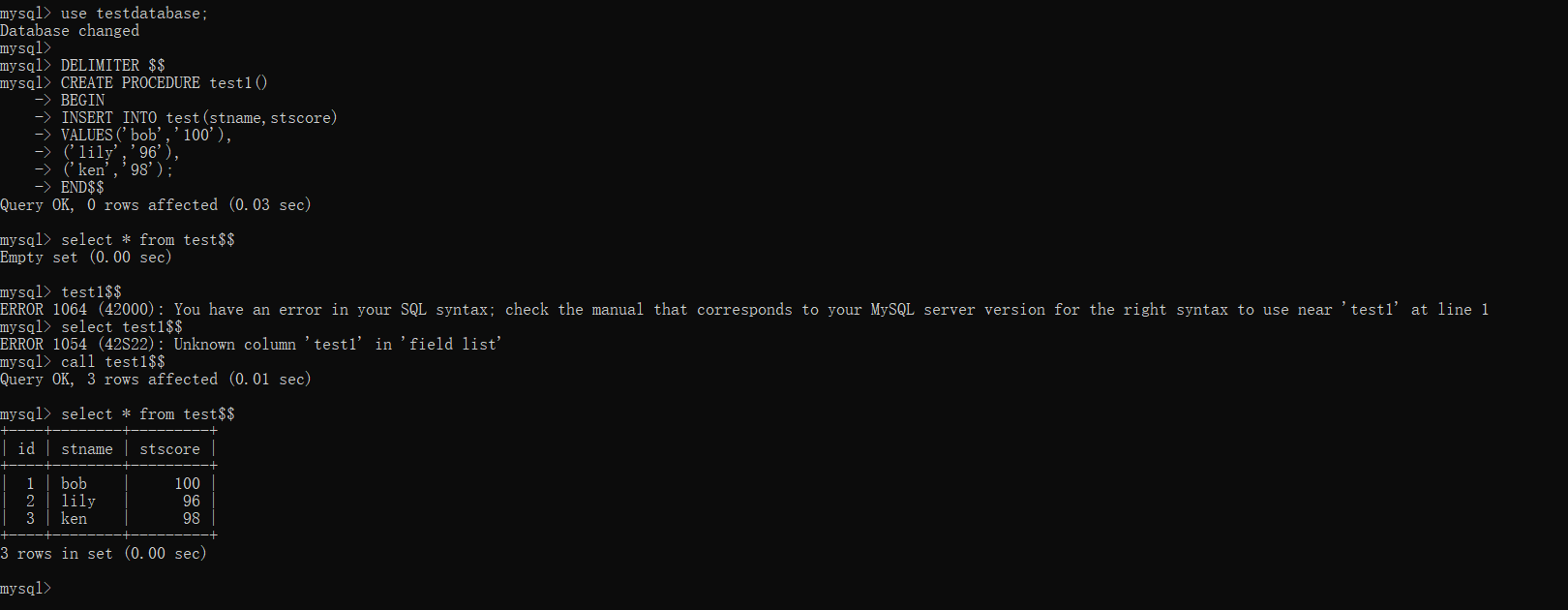
CREATE PROCEDURE test1()
BEGIN
INSERT INTO test(stname,stscore)
VALUES('bob','100'),
('lily','96'),
('ken','98');
END$$这里要注意,其中的方法体是每一句一个
;而上述例子中insert into是一句话,只不过是分的比较碎。调用方法:如果要使用无参存储过程的话只要
call 过程名()即可运行截图如下:
2.参数模式为IN
1
2
3
4
5
6CREATE PROCEDURE test2(IN id INT)
BEGIN
UPDATE test
SET stscore=95
WHERE test.id =id;
END$$这里需要注意的一点是,因为的参数里面起名叫做了id,那么如果我在存储过程体中要使用表中本身的id的话,那么我们就要使用
表名(或表别名).id的结构来调用表中列。还有就是参数可以接受很多个,可以是相同模式的,也可以是不同模式的。
调用方法:如果要使用参数模式为IN存储过程的话只要
call 过程名(与参数同类型的数据或是变量)即可。运行截图如下:

3.参数模式为OUT
1
2
3
4
5
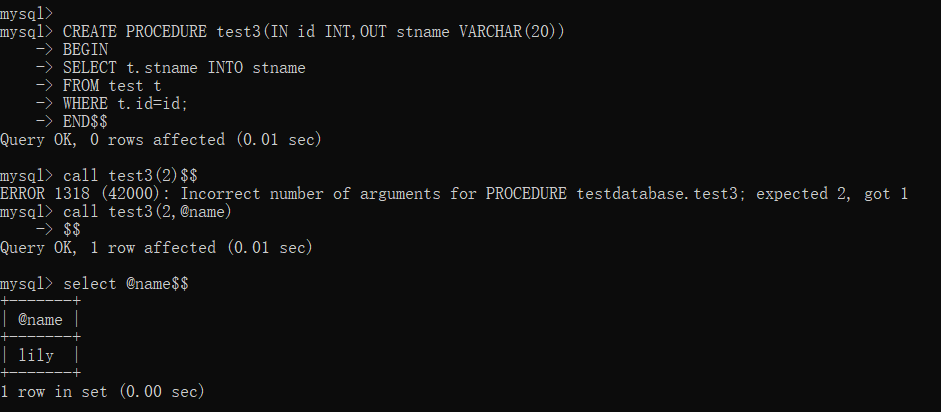
6CREATE PROCEDURE test3(IN id INT,OUT stname VARCHAR(20))
BEGIN
SELECT t.stname INTO stname
FROM test t
WHERE t.id=id;
END$$这里我们利用
select 字段 into 变量名将表中返回的stname注入到参数stname中。调用方法:如果要使用参数模式为OUT存储过程的话必须要
call 过程名(变量),而这个变量是用来存储OUT的输出结果的,如果想查看输出结果那么我们只需要再利用select 变量名即可。但我们一般用不到OUT,因为大多数存储过程都是用来对表进行修改的,所以很少返回参数,除非有比如返回受影响行数的需求时,才会用到OUT模式的参数。运行截图如下:
4.参数模式为INOUT
1
2
3
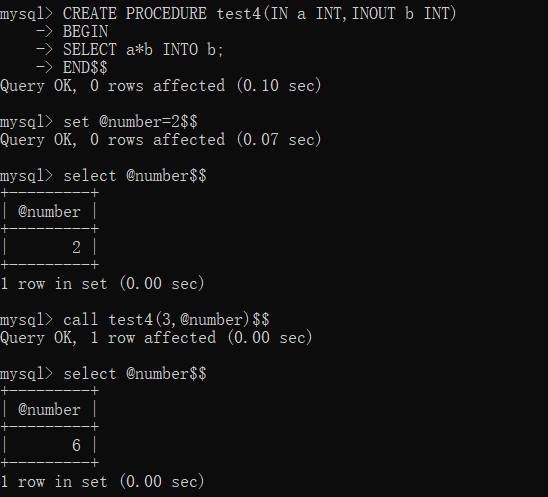
4CREATE PROCEDURE test4(IN a INT,INOUT b INT)
BEGIN
SELECT a*b INTO b;
END$$这里我就不使用表了,直接利用变量进行一个乘法运算了
**调用方法:同OUT模式下调用方法:
call 过程名(变量)运行截图如下:
存储过程的删除
1
DROP PROCEDURE 存储过程名
存储过程的查看
1
SHOW CREATE PROCEDURE 存储过程名
注意:这里并没有
desc procedure的语句。 函数
函数与存储过程的区别在于存储过程可以有0或多个返回,主要用于批量的插入和批量的更新而函数则是有且仅有1个返回,主要用于数据处理后返回一个结果,可以参考sql中自带的
AVG(),MAX(),IF()等函数。 函数的创建
1
2
3
4
5
6DELIMITER $$
CREATE FUNCTION 函数名(参数名 参数类型) RETURNS 返回值类型
BEGIN
函数体
RETURN 值;
END$$调用方法:
select 函数名(参数列表)在函数创建的时候可能会遇到如下报错:
ERROR 1418 (HY000): This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable)具体原因咱也不知道,但是解决方法是有的:
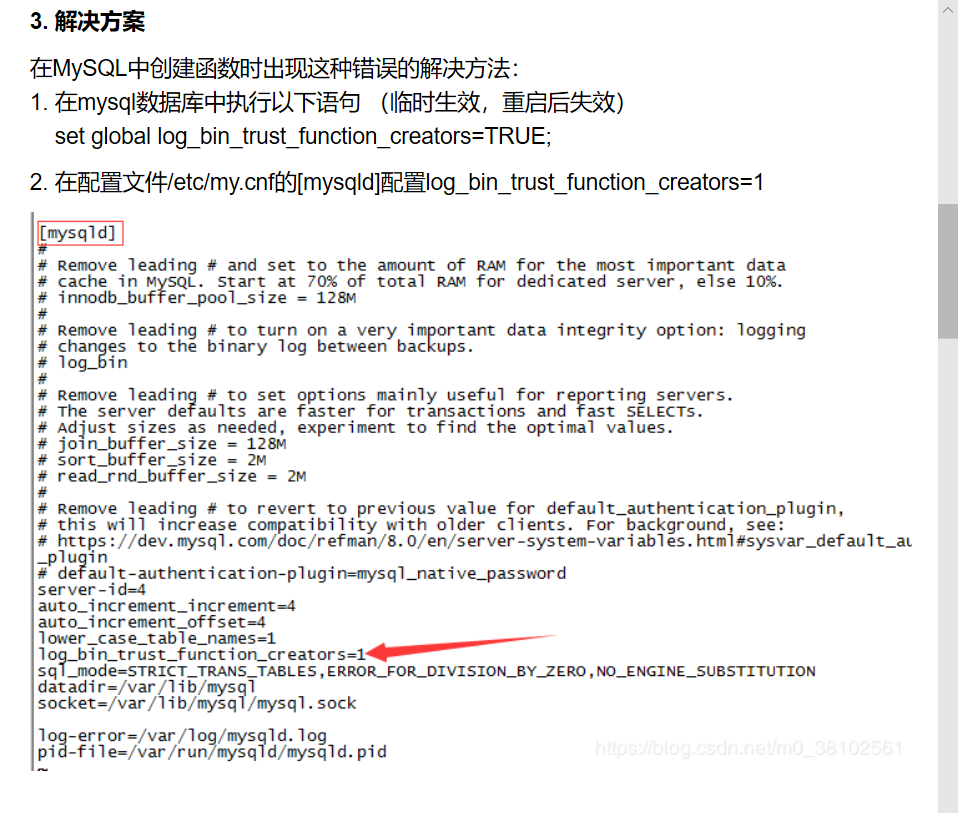
在这里将图中代码贴上:
set global log_bin_trust_function_creators=TRUE;具体事例:
1
2
3
4
5
6
7
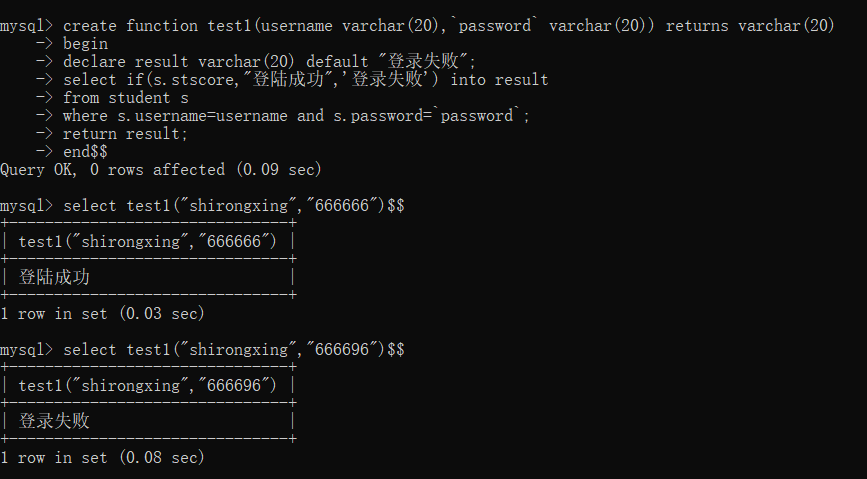
8create function test1(username varchar(20),`password` varchar(20)) returns varchar(20)
begin
declare result varchar(20) default "登录失败";
select if(s.stscore,"登陆成功",'登录失败') into result
from student s
where s.username=username and s.password=`password`;
return result;
end$$这段代码是一个简单的登录验证查询,如果我们的数据库中包含了传入用户的用户名和密码那么我们就返回登陆成功,否则返回登录失败
运行截图如下:
函数的查看
1
SHOW CREATE FUNCTION 函数名;
函数的删除
1
DROP FUNCTION 函数名;
流程控制结构
说白了就是循环和判断,但sql中的循环和判断还是有一些区别的。
判断
判断分两种一个是case的,一个是if的。其中case类似于java中的switch,if等同于java中的if。
1.case
情况1
1
2
3
4
5
6
7
8CASE 变量|表达式|字段
WHEN 要判断的值 THEN 返回的值1或语句1;
WHEN 要判断的值 THEN 返回的值2或语句2;
.
.
.
ELSE 要返回的值n或语句n
END CASE;这种情况下的具体案例可以参考上一篇中
UPDATE的特殊使用方法。其中如果将THEN后面的返回值变为语句的时候需要在每句后面加入;,同时在END后面加入CASE;,下面的情况同理。而THEN后面加入语句的使用方法只限于在BEGIN~END中,即只可以使用在函数和存储过程中。情况2
1
2
3
4
5
6
7
8CASE
WHEN 要判断的条件1 THEN 返回的值1或语句1;
WHEN 要判断的条件2 THEN 返回的值2或语句2;
.
.
.
ELSE 要返回的值n或语句n;
END CASE;此时这种用法类似于IF
2.if
1
2
3
4
5
6
7IF 条件1 THEN 语句1;
ELSEIF 条件2 THEN 语句2;
.
.
.
ELSE 语句n;
END IF基本和第二种情况的case一样。
循环:
循环的标签可以省略,但如果要想使用循环控制语句,就必须使用标签。
1.while:
1
2
3标签:while 循环条件 do
循环体;
end while 标签;类似于java中的while循环。
具体案例:
1
2
3
4
5
6
7
8
9
10
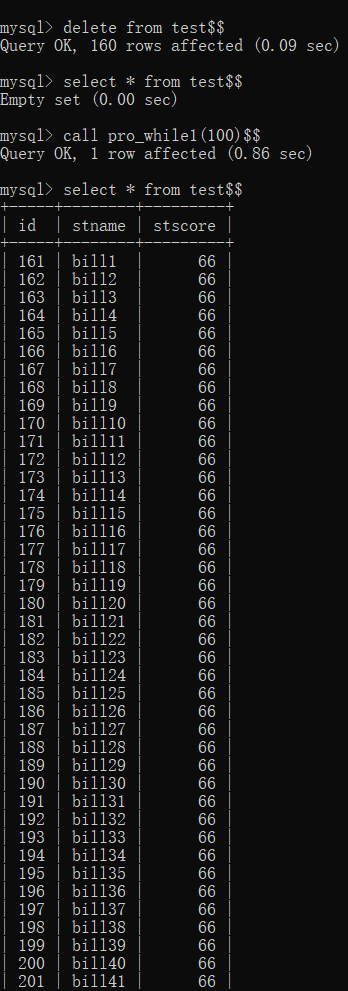
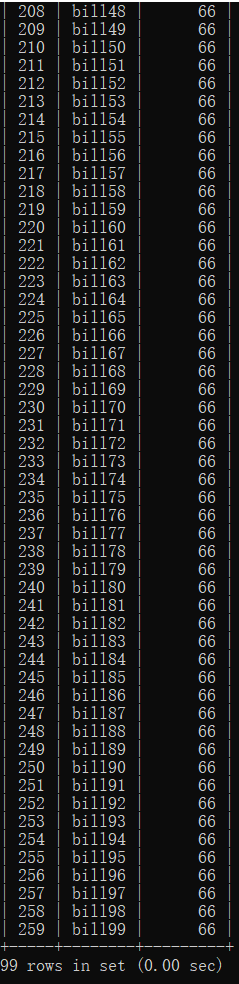
11DELIMITER $$
CREATE PROCEDURE pro_while1(IN insertcount INT)
BEGIN
DECLARE i INT DEFAULT 1;
a:WHILE i<=insertcount DO
INSERT INTO test(stname,stscore)
VALUES(CONCAT("bill",i),66);
SET i=i+1;
END WHILE a;
END$$
CALL pro_while1(100);运行截图如下:
2.loop:
1
2
3标签:loop
循环体;
end loop 标签;loop循环如果不搭配leave使用那么就会成为一个死循环。大致使用流程与while相似,这里就不放具体案例了。
3.repeat:(do while)
1
2
3
4标签: repeat
循环体;
until 结束循环的条件
end repeat 标签;类似于java中的do while循环,即会先执行一次命令再去进入循环,所以至少执行一次。大致使用流程与while相似,这里就不放具体案例了。
循环控制语句:
iterate:(continue)
1
2IF 条件 THEN ITERATE 循环标签;
END IF; leave:(break)
1
2IF 条件 THEN LEAVE 循环标签;
END IF;
总结:
这最后一次的更新中所讲到的事务,视图,存储过程,函数都很相似,都是类似于把一些sql语句或绑定或封装到一起,所以在记忆时要着重区分一下,不要搞混。同时这次里面有很多平时不怎么用到而且很长的单词出现,也要具体的记忆一下。有些不常用的可以了解即可,到用到了再去查。
啰嗦:
这篇文章写完的时候已经是凌晨2.26了,最近几天一直在熬夜看东西,学东西,想要通过更多时间的努力来追补上与学校里大佬们的脚步,虽然我也知道这个过程还很漫长,但千里之行始于脚下,只能一步一步的努力。同时这里我还想啰嗦几句:就计算机专业来说,如果大学四年仅仅是跟着老师走,即使能够把所有的学科成绩都达到最好,得到最高的绩点其实本身的动手能力仍是不强的,如果想要真正学到东西还得是在网上自学。就像前不久看到过的一句话:当一项技术进入到大学的课堂里时,那么这项技术大多已经凉了一半了。
这里附上我个人学习的途径: