
CRF BiLSTM LSTM图解
书接上文,这里主要参考了试图理解LSTM和RNN,在此再次感谢该博主简单明了的解释。
1.LSTM
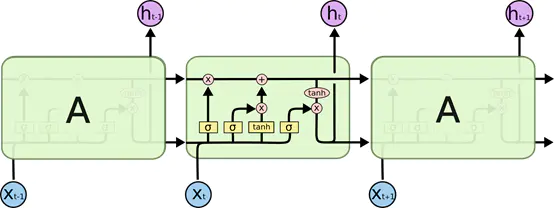
首先我们要知道其大体流程:如上图中的Xt为当前网络输入,ht为当前网络输出,而箭头则表示数据流的流向,我们这里以第二个单元为例,其上一个单元处理后的数据会作为输入输入到当前单元中并与当前单元的输入进行运算。并将运算结果输出的同时传递给下一个单元。
其次就是LSTM中最重要的三个门,其主要是对上面一条的主数据流进行控制与保护。
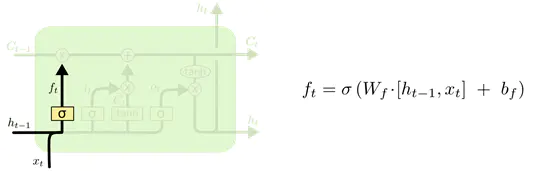
首先是遗忘门,信息输入了之后,σ层就会把信息转化为ft,如果决定要忘记,ft就是0,如果这个信息要保留,则为1,选择部分记忆则按照实际情况输出0~1的数。其中的σ层指的是sigmoid函数层把数据压缩到0到1的范围,0就代笔信息无法通过该层,1就代笔信息可以全部通过。
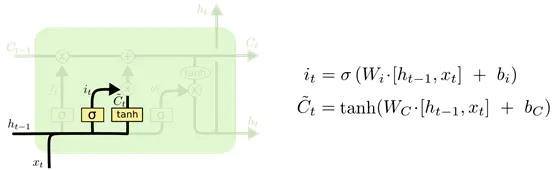
然后是输入门,输入门决定什么信息需要被存储进cell state。上一个输出加上这一次的输入,统一经过σ层,决定要更新啥信息。还要另外经过tanh层,将信息转化为一个新的候选值,两者再相乘,就是cell state(这里的cell state是指的最上面那条主数据流,即传递给下一个单元的数据流)中需要更新的值了。然后通过数据流上的加法和乘法运算,对数据流进行更新,将遗忘门和输入门中对数据的修改进行实现。
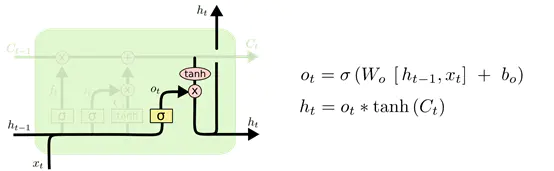
最后是输出门,这里就是将刚刚进行更新完成的数据分为两个部分进行输出,一个部分作为下一个单元的输入传递过去,另一部分作为输出,输出到下一个layer中。
2.BiLSTM
有了上面对于LSTM的内部结构的理解,这里我们就以此为基础对BiLSTM模型的整体结构进行图解。
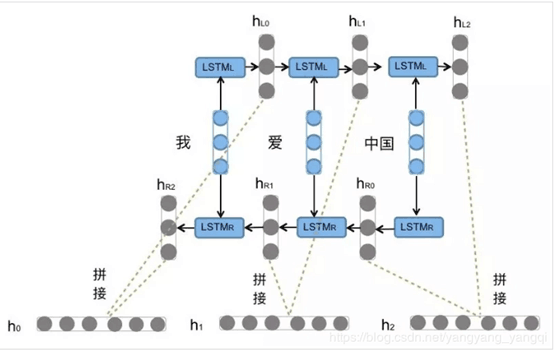
如图所示,BiLSTM就是将两个LSTM模型进行反向并行拼接。将同一个语句中的词向量作为输入层分别派发给正反两个LSTM,然后分别获取二者的输出HLi和HRi,并将二者进行拼接已得到最终的Hi作为输出。以图中的语句为例,在正向的LSTM中,输入的分别为:“我”,“爱”,“中国”,在反向的LSTM中国输入的则为“中国”,“爱”,“我”。而后将二者的输出收尾对立拼接:{[hl0,hr2],[hl1,hr1],[hl2,hr0]}。从而得到了最终输出{h0,h1,h2}。
以上两种模型pytorch中已给出相应的框架代码,只需要定义相关参数即可实现。该函数为:self.lstm = nn.LSTM(),其中有一个bidirectional参数,当其传入的值为true时,构建的LSTM模型为双向模型,即BiLSTM模型。
3.CRF与BiLSTM的对接与原理
首先由上面的BiLSTM模型图解我们了解了BiLSTM的输出结构,而其真实的输出应该为一组组的得分,而我们最后要做的就是在这每一个independent中找出得分最高的那一个标注,作为这个词的输出。结构图如下:
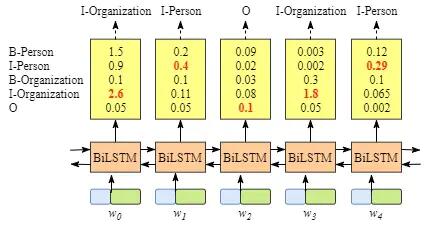
而在当我们选出相应的最高分的标注时,我们却发现上图中I-Organization后面直接选出的是I-Person,由BIOES标注法我们可以知道I-xx一般指代的都是某个词的中间词向量(这里的词向量一般多为单个字或单个字母),所以其后面不应该接另外一个新的标签的中间部分。这样我们也就得出了,如果直接这样输出,那么其对于实体的识别准确度就会大大下降,因为其并没有相关常识的约束。而CRF层在这里则是起到了给予BiLSTM输出以约束的功能。
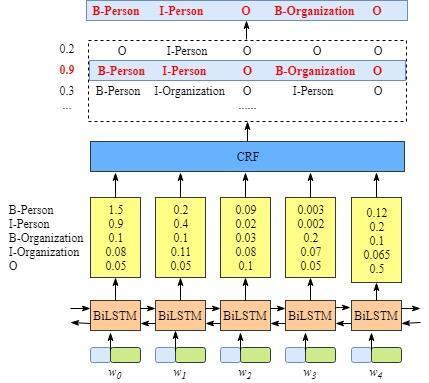
其工作原理为:为一个位置进行标注的过程中可以利用此前已经标注的信息,并且这些约束可以在训练数据时被CRF层自动学习到。而后我们只需要再使用Viterbi对其进行解码即可。
最后
这里还有一个对 Viterbi算法的一个通俗解释,来源于知乎。